Data Science Workflow
Building a minimal data science project in DataCards.
DataCards is a real-time collaboration platform where data experts co-create dynamic, interactive dashboards powered by interconnected Python notebooks.
This document outlines a lightweight workflow tailored for small- to medium-scale data science projects. The emphasis is on modularity, in a collaborative environment built on Python notebooks. By dividing responsibilities across focused notebooks, the workflow also reduces memory footprint, prevents redundancy, and improves maintainability.
Challenge: Most notebook solutions, like Jupyter, work in isolation—shared data and computations must be repeatedly loaded and processed across different notebooks, especially after kernel restarts.
Solution: DataCards enables notebooks to publish and consume data between each other, creating persistent, interconnected workflows that eliminate redundancy and survive environment resets.
Core steps of a Data Science workflow
Data science projects can follow many different approaches depending on their goals and context. One common workflow transforms raw data into actionable data products through these interconnected phases:
- Environment Setup & Dependencies - Establishing a reproducible environment with all necessary tools and libraries
- Data Acquisition & Preparation - Loading, cleaning, and structuring data from various sources, including handling missing data and inconsistencies
- Data Augmentation - Enhancing datasets through feature engineering, synthetic data generation, or external data integration
- Exploratory Data Analysis - Understanding data patterns, relationships, and quality through filtering and analysis - often seen as analytical work rather than software development, but crucial for understanding the data landscape
- Modeling & Business Logic - Applying statistical models, machine learning algorithms, or business rules to extract insights
- Model Evaluation & Validation - Testing model performance, assessing generalizability, and validating results against business requirements
- Data Productization - Transforming insights into operational data products, including dashboards, APIs, automated reports, and decision-support systems that deliver ongoing business value
This workflow is iterative rather than linear - insights from later stages often require revisiting earlier steps, and different project phases may run in parallel or be revisited multiple times.
Organization of Data Science workflows in DataCards
DataCards transforms the traditional monolithic notebook approach by dividing the workflow into specialized, interconnected Python notebooks that communicate through a shared variable system.
Monolithic Data Science Setup vs. Data Science Workflow in DataCards
The following comparison illustrates the key differences between traditional monolithic data science setups and the modular DataCards approach:
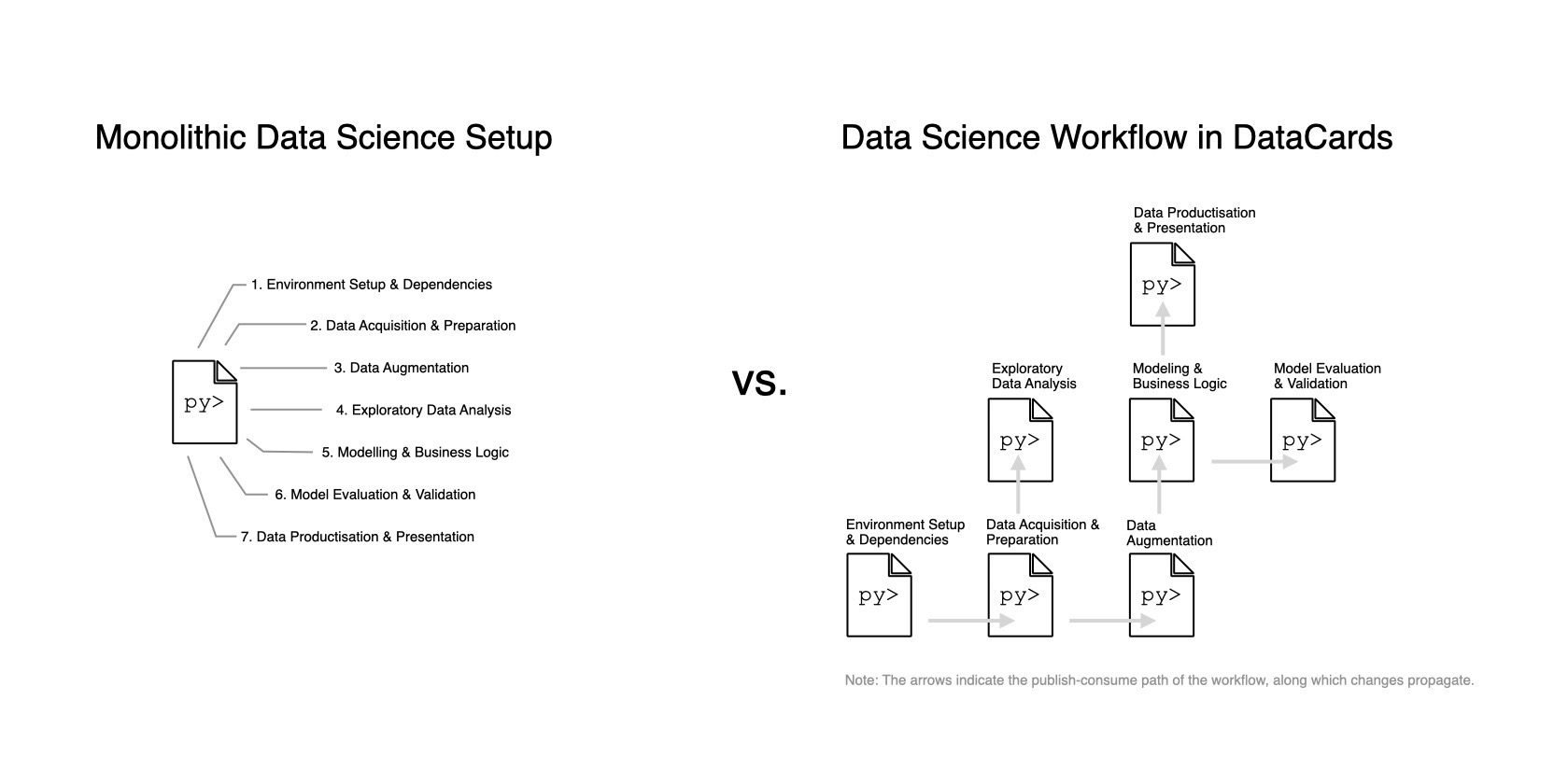
The diagram shows the comparison between a traditional monolithic data science setup (left) and the modular DataCards approach (right), illustrating how the workflow is broken down into interconnected notebooks that communicate through the publish-consume mechanism.
Note: The arrows indicate the publish-consume path of the workflow, along which changes propagate.
Instead of cramming all steps into a single notebook that becomes unwieldy and memory-intensive, DataCards enables a modular architecture where:
- Each notebook focuses on a specific workflow phase (data preparation, modeling, visualization, etc.)
- Notebooks share data and results through datacards’ publish/consume mechanism
- Variables persist across notebook sessions and kernel restarts
- The entire workflow maintains logical connections while allowing independent development and execution
This modular structure addresses critical limitations of traditional monolithic setups:
- Memory Management: Prevents kernel crashes and reduces RAM consumption by distributing computational load across focused notebooks
- Reproducibility: Ensures consistent results through persistent variable sharing, regardless of individual notebook restart cycles
- Maintainability: Enables targeted debugging and updates without disrupting the entire analysis pipeline
- Persistence: Maintains data and variables across notebook sessions using DataCards variables
- Scalability: Allows teams to iterate quickly on specific components and recover from failures efficiently without rerunning entire workflows
The result is a collaborative environment where multiple notebooks work together seamlessly while maintaining clear separation of concerns - essential for both exploratory analysis and production data products.
Trade-off between the number of notebooks/RAM/positioning
Balancing Modularity and Performance: The Notebook Architecture Trade-off
One of the most critical decisions in DataCards project design is determining the optimal number of notebooks. This choice involves a fundamental trade-off between modularity benefits and system resource consumption.
The Modularity-Performance Tradeoff:
On one hand, too few notebooks create monolithic structures that undermine DataCards’ core advantages: individual notebooks become unwieldy and hard to maintain, memory usage concentrates in single kernels increasing crash risk, and collaboration becomes difficult when multiple developers need to work on the same large notebook. Code becomes harder to debug, and the ability to isolate and restart specific workflow components is lost.
On the other hand, too many notebooks introduce significant system overhead. Each notebook consumes approximately 200MB of RAM regardless of its content, meaning that even 20 empty notebooks can consume around 4GB of system memory. This overhead grows quickly and can lead to performance degradation, increased complexity in managing dependencies, and higher cognitive load for developers navigating the project structure.
Note: Depending on what you do in each notebook, ~20 notebooks (even without user code execution) can already consume around 4 GB of RAM — clean separation is essential for stability and reproducibility.
| Approach | Position set in FE (automatically set in card store) | Position set in code (set in notebook) |
|---|---|---|
| Many notebooks (≈1 card per notebook) | Pros: Max isolation, easy to reorder in frontend. Cons: Highest RAM (more notebooks). Use when: Experiment-heavy, designing projects | Pros: Per-card logic in code. Cons: Highest RAM + positions fixed in code; harder to change and find. Use when: Deterministic, code-driven layout per card, clear separation between cards on a logic level needed |
| Few notebooks (grouped) (many cards per notebook) | Pros: Low RAM. Cons: FE cannot set per-card positions for cards emitted by a single notebook. Use when: not implemented/cannot be used now | Pros: Lowest RAM, positions repeatable from code. Cons: Least flexible for design; drag&drop useless; code changes needed to reorder. Use when: Stable layouts, strict determinism. (Default) |
Next Steps
Ready to implement this workflow in your own project? Check out our Data Science Workflow Tutorial for a hands-on guide with step-by-step examples.